From Human-First Data Systems to the Agentic Data Stack
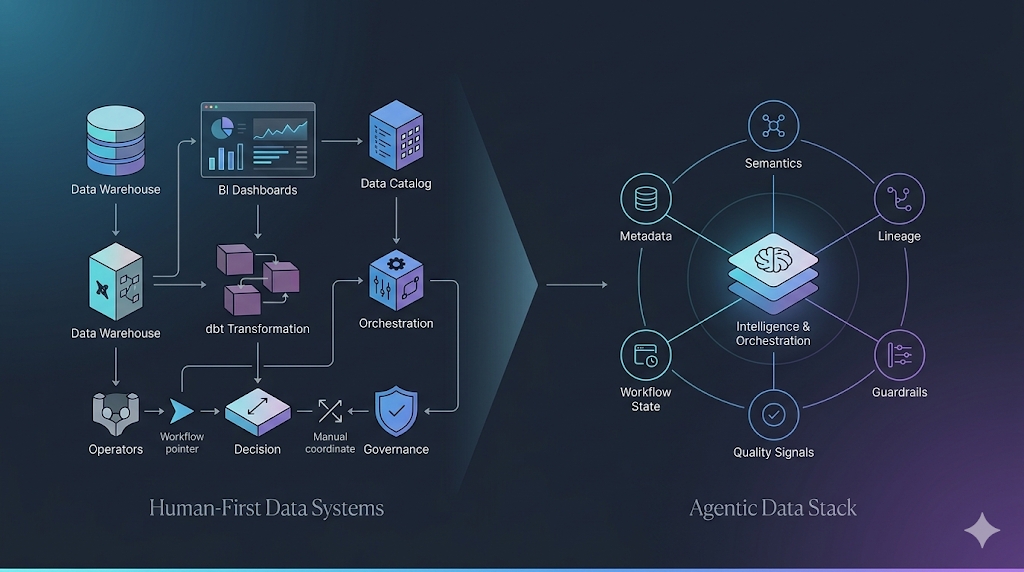
For most of the modern data era, the stack was built around human operators.
Humans wrote transformations. Humans reviewed lineage. Humans interpreted semantic definitions. Humans coordinated workflows across warehouses, orchestration systems, catalogs, BI tools, and governance processes. Even as the stack became more modular and more powerful, the operating model remained the same: the tools were built for people to drive directly.
That model gave us the modern data stack. It created a strong foundation for analytics engineering, semantic modeling, data quality, and platform standardization. But it also created a limit. The stack became increasingly rich in tools, while the burden of coordination remained highly manual.
Now a new shift is starting to take shape.
The next phase is not simply AI on top of dashboards. It is not only natural language interfaces for querying data. And it is not adequately described by the category of “AI SQL client.”
What is emerging is something larger: the Agentic Data Stack.
The limits of the “AI SQL client” frame
“AI SQL client” is a useful phrase if the product’s core job is query generation. It signals speed, convenience, and accessibility. But it is too small a frame for the broader operational reality of data engineering.
Real data work does not stop at generating SQL.
Teams still need to decide which datasets are canonical. They need to understand semantic definitions. They need to inspect lineage, validate assumptions, manage quality checks, coordinate workflows, monitor outputs, and improve how execution happens over time.
A product framed only as an AI SQL client is implicitly framed as a thin layer above the warehouse. That may help with prompting and query generation, but it does not fully address how engineering work actually gets done.
This is why the category starts to break down as soon as the scope expands from asking questions to operating workflows.
What makes a data engineering agent different
A data engineering agent is not just a better query assistant.
A real agent needs a richer operating environment. It needs access to structured context and the ability to reason across the system it is acting inside.
That means context such as:
- metadata about assets and schemas
- semantic definitions and governed metrics
- lineage between upstream and downstream systems
- workflow state and orchestration signals
- quality checks and validation rules
- execution guardrails and policies
Without these layers, an AI system may produce plausible-looking output, but it cannot reliably participate in production workflows.
This is the difference between fluent generation and useful operation.
The more a team wants AI to move from suggestion toward execution, the more structure the environment needs to provide.
The rise of the Agentic Data Stack
The modern data stack was built around modular specialization. Warehouses, transformation tools, BI systems, semantic layers, catalogs, and orchestrators each developed into distinct layers.
The Agentic Data Stack does not replace those layers. Instead, it changes how they function together.
In an agentic architecture, these layers become part of the shared operating context for agents. Metadata is not just for documentation. Semantics are not just for analysts. Lineage is not just for governance. Workflow state is not just for operators.
All of these become inputs into how agents plan, reason, act, validate, and learn.
That shift has two important implications.
First, AI becomes less about isolated interactions and more about workflow participation. The value is not only in answering a question, but in helping move work from intent to execution.
Second, the stack itself becomes more important, not less. Agentic systems do not reduce the need for structure. They increase it. The better the semantics, lineage, governance, and workflow visibility, the more reliable the agent becomes.
In other words, the Agentic Data Stack is not a shortcut around data infrastructure. It is what makes trustworthy agent behavior possible.
Why Datus is repositioning
This is the context behind the positioning shift for Datus.
Datus should not be understood as just another AI data tool, and it should not be reduced to an AI SQL client. Those labels point to a much narrower mental model than the one we are building toward.
Datus is better understood as a data engineering agent.
That means a system designed to work across:
- context discovery
- semantic understanding
- task planning
- workflow execution
- validation and quality
- continuous improvement
It also means Datus is being built for teams that want more than chat-based convenience. The goal is not to generate isolated answers. The goal is to support real engineering work with structure, context, and control.
This is why the broader narrative matters. Datus is not only a product story. It is part of a larger architectural shift toward agent-ready data systems.
Human-first to human-and-agent systems
The previous generation of tooling was optimized for human-first operation. That model is not disappearing. Humans will remain central to how data systems are designed, governed, and improved.
But the operating model is changing.
The next generation will increasingly be built for humans and agents together:
- humans providing intent, oversight, and judgment
- agents handling structured reasoning, repetitive execution, and workflow support
- systems supplying the context and guardrails needed to keep the whole process reliable
This is the direction that matters.
If the modern data stack was about assembling the right set of tools for people, the Agentic Data Stack is about creating an environment where agents can participate meaningfully in data work.
That is the shift Datus is aligning with.
Datus is a data engineering agent for the Agentic Data Stack.
Conclusion
The industry does not need more vague AI messaging around data. It needs sharper categories.
Not every AI layer on top of a warehouse is an agent. Not every SQL assistant is a new operating model. And not every natural language interface changes how data systems work.
But something real is changing.
As context becomes more structured and workflows become more observable, the stack is becoming more ready for agents. That opens the door to a new class of systems—ones that can move beyond chat and into actual operational support.
That is the space Datus is moving into.
And over time, we think more teams will stop asking whether they need “AI for data” and start asking a better question:
What does our stack need in order to support reliable agents in production?
If you're exploring this shift
If you're exploring how metadata, semantics, lineage, and orchestration can become an operating environment for agents—not just human operators—Datus is building in that direction.
Related Reading
- What Is a Data Engineering Agent? A Practical Guide with Datus
- Data Engineering Agent Architecture: From Prototype to Production with Datus
- 7 High-Impact Data Engineering Agent Use Cases (Powered by Datus)
- The Layered Subagent Architecture for Data Engineering Agents
- SQL agents are broken without context. Meet Datus.
Start with Datus
- GitHub: https://github.com/Datus-ai/Datus-agent
- Docs: Datus Docs
- Main site: https://datus.ai