Agentic ETL: What Changes Beyond Traditional ETL
Traditional ETL is built around predefined logic. You map sources, define transformations, schedule jobs, and monitor failures. That model still matters. But it starts to break down when pipelines depend on messy context, changing business definitions, cross-system dependencies, and operational judgment.
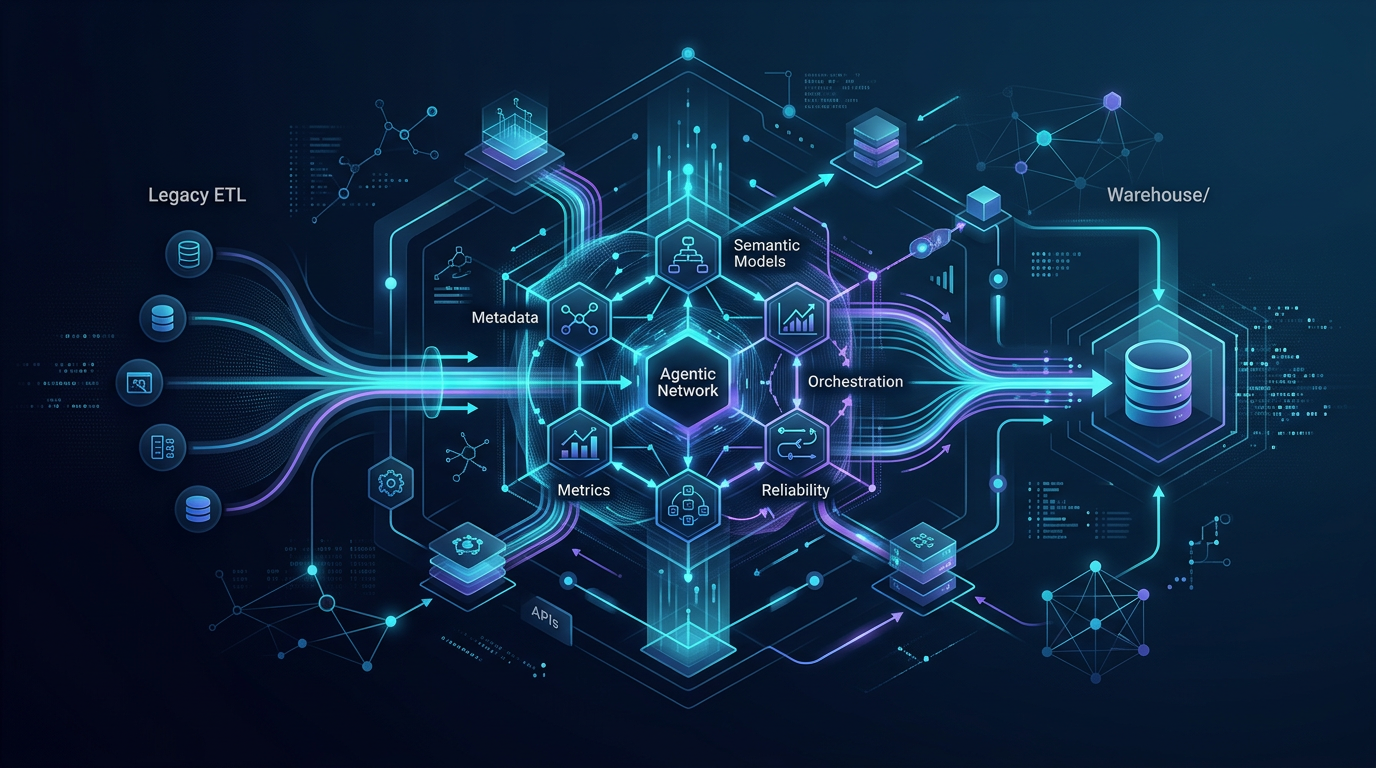
Agentic ETL adds a new layer: systems that can reason across metadata, validation history, semantic context, and workflow state before deciding what to do next. The shift is not from engineering to magic. It is from static pipeline execution to context-aware, workflow-aware automation with guardrails.
For data teams, that changes the job of ETL in a few important ways:
- pipelines can adapt based on what the system knows, not only what was hardcoded
- validation can become part of the decision loop, not just a post-run check
- workflow state can guide next actions, retries, escalations, and routing
- humans move from manually operating every step to supervising higher-value exceptions
This article explains what changes, where agentic ETL helps most, and where teams still need explicit governance.
What is agentic ETL?
Agentic ETL is an ETL model where AI agents can use structured context to plan, validate, and coordinate parts of a data workflow instead of only executing fixed steps.
That context may include:
- schema and metadata information
- lineage and upstream/downstream dependencies
- semantic definitions and metric logic
- data quality expectations and prior failure patterns
- workflow state such as task status, retries, approvals, and handoffs
In a traditional ETL pipeline, the system runs the steps it was given.
In an agentic ETL workflow, the system can also reason about questions like:
- Did the source schema change in a way that affects this transformation?
- Is this validation failure a hard stop or a known low-risk anomaly?
- Which downstream models or dashboards are affected?
- Should the next step be rerun, rewritten, paused, or escalated?
- Which tool or workflow should be invoked based on the current state?
That is the real difference. Agentic ETL is not just ETL with an AI label. It is ETL with context management, reasoning, and execution control.
Traditional ETL vs agentic ETL
| Dimension | Traditional ETL | Agentic ETL |
|---|---|---|
| Execution model | Predefined steps and schedules | Dynamic planning within guardrails |
| Handling change | Requires manual updates to logic | Can detect context shifts and propose or trigger next actions |
| Validation | Often runs after transformations | Becomes part of an iterative decision loop |
| Workflow awareness | Limited to task orchestration state | Reasons across workflow state, dependencies, and failure history |
| Use of metadata | Often separate from execution logic | Metadata and lineage inform decisions directly |
| Human role | Manual operator for many edge cases | Supervisor for exceptions, approvals, and policy boundaries |
| Reliability model | Static rules plus monitoring | Structured context, guardrails, evaluation, and human-in-the-loop review |
What actually changes in practice
The easiest way to understand agentic ETL is to look at the operational changes.
1. Context becomes part of execution
In traditional ETL, context is usually scattered across runbooks, tickets, catalogs, dashboards, and the heads of senior engineers.
In agentic ETL, more of that context is available to the system at execution time. That includes table definitions, data owners, semantic logic, lineage, and known data quality constraints.
This matters because ETL failures are rarely just syntax problems. They are often context problems:
- a column still exists but its business meaning changed
- a source table is complete enough for one downstream model, but not another
- a metric definition changed and now the same transformation is logically wrong
- a late-arriving dataset should delay one workflow but not block the full DAG
Static ETL treats these as external issues. Agentic ETL can treat them as inputs to the workflow itself.
2. Validation is no longer a separate afterthought
Traditional pipelines often validate after loading or transforming data. If checks fail, the pipeline breaks or alerts a human.
Agentic ETL changes that pattern by allowing validation to influence the next action. A system can inspect failed checks, compare them to past incidents, review lineage impact, and decide whether to:
- retry a step
- quarantine a dataset
- use an alternate branch of the workflow
- request human approval
- stop downstream publication
This is a big operational change. Validation stops being a binary pass/fail gate and becomes part of a broader reasoning loop.
3. Workflow state becomes actionable context
Workflow orchestration already tracks state, but traditional ETL usually treats that state mechanically: queued, running, failed, succeeded.
Agentic ETL can use workflow state more intelligently. It can reason about:
- how long a task has been waiting
- whether the same step failed for a similar reason before
- whether downstream consumers are blocked
- whether an approval is still pending
- which remediation path is appropriate for this exact workflow state
That means the workflow is not just a sequence of tasks. It becomes a system the agent can inspect and act on with more precision.
4. ETL shifts from rigid automation to bounded autonomy
The best way to frame agentic ETL is not “fully autonomous pipelines.” That oversells the model and underestimates data engineering reality.
A better frame is bounded autonomy:
- the system can plan within defined policies
- the system can use tools and context to resolve known classes of issues
- the system can escalate when confidence is low or impact is high
- the system still operates with human-in-the-loop control for risky changes
That is how AI data pipeline automation becomes useful in production. Not by removing control, but by making routine decisions faster and better informed.
Three examples of agentic ETL in the real world
Example 1: Schema drift with downstream impact
A source application adds a new status field and deprecates an older column. A traditional ETL job may fail hard, or worse, keep running while silently producing degraded output.
An agentic ETL workflow can:
- detect the schema difference
- inspect lineage to see which models depend on the changed field
- review semantic definitions to understand whether the business logic is affected
- propose a transformation adjustment or route the issue to an engineer
- pause only the impacted downstream branch instead of the entire workflow
The value is not “AI fixed everything.” The value is that the system understands more of the context around the failure before acting.
Example 2: Data quality anomaly during incremental load
A daily incremental load succeeds technically, but row counts are 38% below the historical range.
Traditional ETL may mark the job as green if no explicit threshold exists, or red if a static threshold is breached.
An agentic ETL workflow can check:
- whether a holiday or seasonal event explains the drop
- whether upstream ingestion is delayed
- whether similar anomalies were accepted previously
- which dashboards and metrics would be affected
- whether the right response is retry, defer, annotate, or escalate
That leads to more reliable automation because the system is reasoning with state and history, not only one isolated metric.
Example 3: Failed transformation in a multi-step workflow
A transformation step fails halfway through a larger pipeline that includes ingestion, modeling, testing, and downstream publication.
Traditional ETL usually routes this to an engineer or triggers a fixed retry policy.
An agentic ETL workflow can choose among multiple next steps based on workflow state:
- rerun only the failed segment
- run a lightweight diagnostic query
- compare the error to known failure patterns
- hold publication while allowing unaffected upstream tasks to continue
- prepare a remediation summary for human approval
This is where workflow-state reasoning matters most. The system is not just rerunning jobs. It is coordinating the workflow based on what happened and what matters next.
Where agentic ETL helps most
Agentic ETL is most valuable in environments where pipelines depend on changing context, not just fixed mappings.
Strong candidates include:
- multi-source pipelines with frequent schema evolution
- semantic-layer or metrics-driven analytics workflows
- cross-team data products with many downstream dependencies
- operations-heavy pipelines where retries, validations, and incident handling consume real engineering time
- environments where metadata, lineage, and governance already exist but are not connected to execution
If a pipeline is tiny, stable, and rarely fails, traditional ETL may be enough. Agentic ETL matters more as workflow complexity and context complexity increase together.
What does not change
Agentic ETL does not eliminate core data engineering disciplines.
You still need:
- explicit schemas and contracts
- reliable observability
- quality checks and evaluation
- governance and access controls
- clear ownership and escalation paths
- human review for high-impact decisions
In fact, these become more important. Agents perform better when the operating environment is structured. Poorly defined semantics, weak metadata, and missing guardrails do not disappear when AI is added. They become bigger reliability risks.
A practical checklist for evaluating agentic ETL
Use this checklist to decide whether your ETL environment is ready for a more agentic model.
Architecture and context
- Do you have accessible metadata for schemas, assets, and ownership?
- Can the system inspect lineage across upstream and downstream dependencies?
- Are metric definitions or semantic models available where relevant?
- Is workflow state exposed in a usable way, not just buried in logs?
Validation and reliability
- Are data quality checks connected to execution decisions?
- Can failures be classified by impact and confidence?
- Do you have clear escalation rules for when humans must approve next actions?
- Can the system evaluate whether an automated remediation worked?
Governance and control
- Are tool permissions scoped appropriately?
- Are actions auditable?
- Are risky workflow changes gated behind approval?
- Is there a defined human-in-the-loop path for ambiguous or high-blast-radius cases?
If most answers are no, start by improving context and control. Agentic ETL works best when it is grounded in structured systems, not when it is asked to compensate for missing foundations.
Why this matters for AI data pipeline automation
The broader AI data pipeline automation conversation often focuses on speed: faster pipeline creation, faster debugging, faster delivery.
Speed matters, but reliability matters more.
What makes agentic ETL different is that it creates a path from context to execution. Instead of treating ETL as a rigid script plus a human escalation queue, it allows systems to reason about what is happening, what changed, what is affected, and what action is appropriate next.
That is a more useful model for production data workflows.
It also aligns with where data teams are heading: not toward black-box autonomy, but toward systems that combine structured context, workflow-aware execution, and practical guardrails.
Next steps
If this article maps to what your team is seeing, the next useful step is not more AI hype. It is a clearer architecture for reliable automation.
- Read the pillar article on AI Data Pipeline Automation: Use Cases, Architecture, and Tradeoffs
- Explore workflow docs and pipeline examples to see how context, validation, and execution can work together in real data workflows
FAQ
Is agentic ETL just another name for ETL automation?
No. Traditional ETL automation usually means scheduled execution of predefined logic. Agentic ETL adds reasoning across context, validation, and workflow state so the system can choose among bounded next actions.
Does agentic ETL replace orchestration tools?
Not necessarily. Orchestration still matters. Agentic ETL builds on workflow systems by making them more context-aware and adaptive rather than replacing scheduling, dependencies, or operational controls.
Is agentic ETL safe for production?
It can be, but only with guardrails. Production use requires scoped tool access, observability, approval paths, and clear policies for when automation can act versus when a human must review.
What data teams benefit most from agentic ETL?
Teams with complex, changing, cross-system workflows benefit most. The value rises when pipelines depend on metadata, lineage, semantics, and operational history that cannot be captured cleanly in static rules alone.
What is the biggest mistake teams make when adopting agentic ETL?
Treating it like a prompt layer on top of fragile pipelines. Reliable agentic ETL depends on structured context, quality signals, workflow visibility, and execution guardrails.
Final takeaway
Traditional ETL is about moving and transforming data through predefined paths. Agentic ETL is about making those paths more adaptive by allowing systems to reason across context, validation, and workflow state.
That does not remove the need for engineering discipline. It raises the value of it.
The teams that benefit most will be the ones that treat agentic ETL as a reliability and execution architecture, not as a shortcut.
engineering article titled 'Agentic ETL: What Changes Beyond Traditional ETL'. Show a modern data pipeline control plane with flowing nodes for extract, transform, validate, lineage, semantic context, and workflow state. Contrast a rigid linear ETL path on one side with a context-aware adaptive agentic workflow on the other. Visual style: minimal, high-trust, systems-oriented, dark-on-light or subtle dark UI accents, suitable for an enterprise AI data platform blog. No cartoon robots, no hype visuals, no consumer AI aesthetic."