What Autonomous Data Engineering Actually Looks Like in Practice
Autonomous data engineering is easy to describe badly. The bad version sounds like this: ask an AI for what you want, and it builds pipelines, fixes models, updates dashboards, and keeps production healthy on its own.
That is not how serious teams should think about it.
Autonomous data engineering is the practical use of agents to carry parts of data work from intent to execution, using structured context, tool access, and explicit guardrails. The point is not maximum autonomy. The point is to reduce repetitive manual work without losing reliability, reviewability, or control.
For most teams, that means the best implementations do not start with full pipeline ownership. They start with narrow, high-friction workflows where engineers repeatedly reconstruct the same context: finding the right assets, tracing lineage, checking metric definitions, drafting transformations, validating changes, and routing the next action.
That is where agentic data engineering becomes useful. Not as a chatbot. Not as a one-prompt data platform. As an operating model for turning context into execution.
What autonomous data engineering is — and what it is not
The cleanest way to frame the category is this:
What it is
- agents participating in real data workflows
- bounded execution across existing systems and tools
- work grounded in metadata, semantics, lineage, and workflow logic
- human-in-the-loop review for higher-risk actions
- reusable context that improves over time
What it is not
- replacing all data engineers
- uncontrolled production changes
- prompt-only automation with no system memory
- generic NL2SQL wrapped in a new label
- black-box execution with unclear reasoning
That distinction matters because many teams are not actually trying to automate “everything.” They are trying to remove the most expensive forms of manual coordination.
What this looks like in practice
In practice, autonomous data engineering usually looks less dramatic and more useful than the hype version.
A team keeps its warehouse, dbt project, BI layer, catalog, semantic definitions, observability tooling, and approval workflows. On top of that, it adds agents that can do four things well:
- Understand the request in operational terms
- Gather the right context across the stack
- Propose or execute the next bounded step
- Surface work for review, correction, or approval when needed
Instead of giving engineers another interface to chat with, the system helps move work through the actual workflow.
A practical flow often looks like this:
- A request comes in: fix a broken metric, add a new transformation, investigate a failed dashboard, or speed up a recurring workflow.
- The agent identifies the relevant tables, models, metrics, lineage, documentation, and prior patterns.
- It proposes a plan based on known context rather than guessing from names alone.
- It drafts SQL, tests, documentation, or workflow changes.
- It validates the result against known rules, dependencies, or expectations.
- It either asks for approval or triggers the next approved action.
- Engineers review the outcome, refine the context, and the system gets better at similar work later.
That is much closer to the real value: not “AI did everything,” but “the system carried 60% of the coordination burden without dropping reliability.”
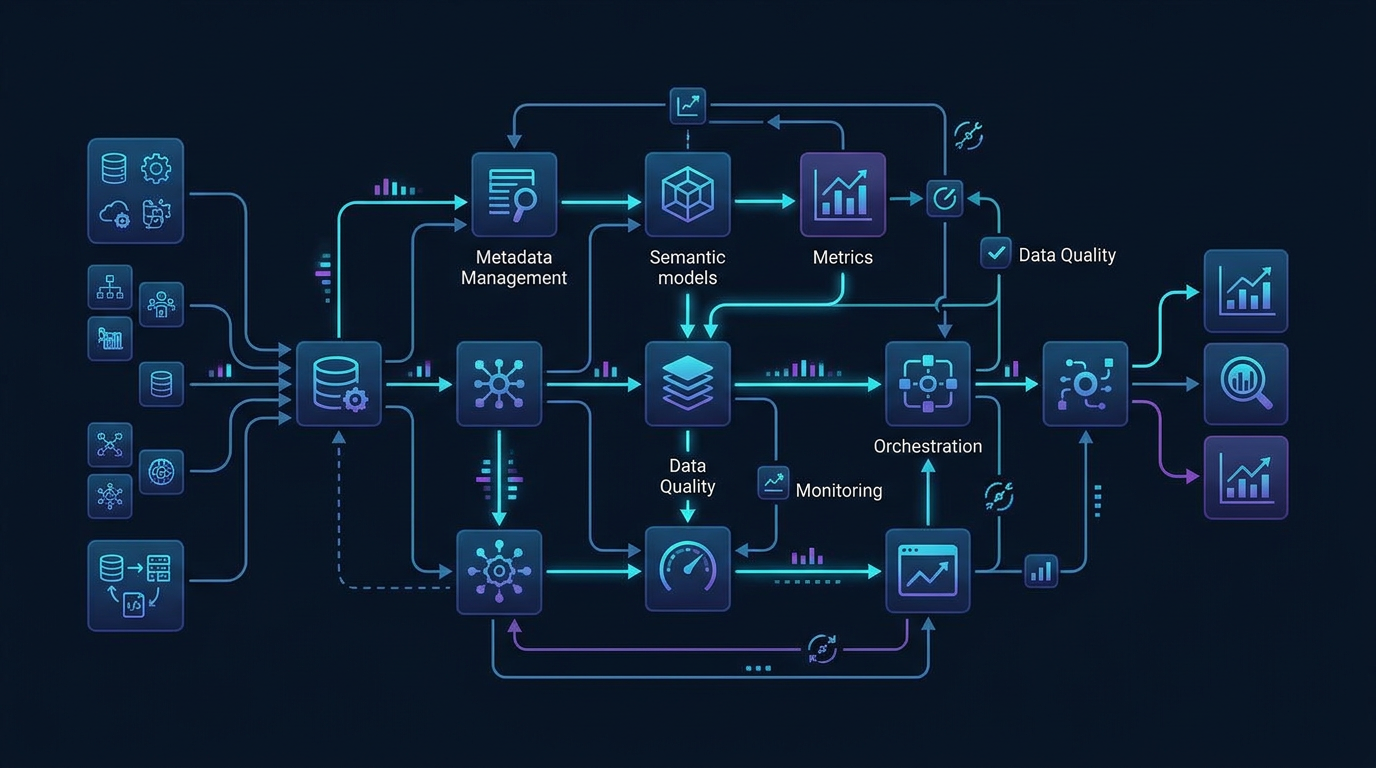
A concrete operating model for autonomous data engineering
The most useful way to think about autonomous data engineering is as a layered operating model.
Layer 1: Context
This is the foundation. Agents need access to more than schemas and table names. They need:
- metadata and catalog context
- semantic models and business definitions
- lineage and dependency relationships
- reference SQL and known workflow patterns
- quality rules, ownership, and governance signals
- prior corrections and team conventions
Without this layer, autonomy is mostly guesswork.
Layer 2: Reasoning
The agent has to interpret the request against the real environment.
That includes:
- mapping business language to technical assets
- distinguishing canonical metrics from lookalikes
- identifying valid joins, grains, and downstream impact
- choosing the right workflow path instead of only generating code
This is where semantic-aware and lineage-aware reasoning matter more than generic language fluency.
Layer 3: Execution
Useful autonomy requires action, but bounded action.
That means the agent can help with tasks like:
- drafting transformations
- generating tests
- preparing documentation updates
- running approved checks
- routing work through orchestration or workflow tools
- preparing pull requests or change proposals
The important point is that execution is tied to permissions, environments, and approval logic.
Layer 4: Oversight
Serious systems keep humans in the loop where they should be.
Oversight usually includes:
- review checkpoints for high-impact changes
- logs of what the agent used and why
- approval gates for production actions
- evaluation against correctness, not just fluency
- a way to update the context layer when the agent gets something wrong
That is what turns autonomous data engineering into reliable automation instead of fast error generation.
Example 1: Adding a new business metric
A product team asks for a new weekly activation metric by segment.
In a traditional model, a data engineer might:
- search docs and dashboards for existing definitions
- ask analysts whether similar logic already exists
- inspect dbt models and source tables
- draft SQL and transformation logic
- validate the metric with stakeholders
- update documentation and dashboards
That is reasonable work, but a lot of it is context reconstruction.
In an autonomous or agentic setup, the flow can change:
- the agent identifies related entities, existing activation logic, and similar metrics
- it checks whether a canonical semantic definition already exists or whether this is a net-new metric
- it proposes the right source model, grain, dimensions, and filters
- it drafts model changes and test cases based on existing conventions
- it flags ambiguities that still need human definition
- it prepares the artifact set for review rather than starting from a blank page
The engineer still owns the decision quality. But the system compresses the time spent collecting context and scaffolding the work.
Example 2: Investigating a dashboard regression
A revenue dashboard drops 14% after a model deployment.
Without a context-aware agent, the response is often manual and fragmented:
- someone checks orchestration logs
- someone else inspects dbt runs
- another person compares dashboard queries
- the team tries to reconstruct what changed and what downstream assets were affected
A more autonomous system can help narrow the problem faster:
- trace lineage from the impacted dashboard back to the changed model
- identify which metrics and dimensions depend on that model
- compare prior and current transformation logic
- surface recent workflow changes that touched the same path
- suggest the most likely breakpoints and the safest validation steps
That does not remove the need for engineering judgment. It removes a lot of wasted search time.
Example 3: Accelerating repetitive pipeline work
Many data teams have recurring implementation work that is predictable but time-consuming:
- creating similar ingestion or transformation patterns
- adding documentation and tests to new models
- updating downstream references after schema changes
- preparing routine quality checks
- cleaning up obvious anti-patterns in SQL or model structure
These are good candidates for bounded autonomy because the workflow is known, the constraints are usually visible, and the cost of drafting assistance is high.
In this kind of setup, the agent is not inventing a new architecture. It is applying existing patterns with context.
That is an important dividing line. Reliable autonomy usually scales faster from known workflows than from open-ended generation.
Why the workflow matters more than the interface
A lot of AI-for-data products are still framed around the interface: ask a question, get an answer.
That can be useful for discovery. It is not enough for engineering.
Data engineering work is workflow-shaped. It involves:
- discovery
- interpretation
- planning
- implementation
- validation
- approval
- monitoring
If autonomy stops at the answer layer, the human still has to carry the operational burden across the rest of the workflow. That is why the more useful systems are workflow-aware. They help the team move from intent to action, not just from question to generated text.
This is also why Datus’s broader framing is directionally strong. The value is not in a generic assistant. It is in connecting structured context, workflow automation, semantic awareness, lineage, and execution with guardrails.
Where autonomous data engineering works best first
Most teams should not begin with the most sensitive production workflows. They should start where three conditions are true:
1. The workflow is frequent
If the task happens every week, the payoff from reusable context is much higher.
2. The context already exists, but is fragmented
Agents work best when the knowledge is there, but spread across catalogs, semantic models, docs, lineage, dashboards, and team memory.
3. The action can be bounded
Good early candidates are tasks where permissions, rollback paths, and review points are clear.
Examples include:
- asset discovery and explanation
- SQL and model scaffolding
- test generation
- lineage-based impact analysis
- dashboard and metric troubleshooting
- workflow preparation for human review
Those are usually better starting points than autonomous production schema changes.
What has to be true for this to work reliably
Autonomous data engineering is not mainly a model-quality problem. It is a systems-design problem.
A team usually needs the following:
Structured context
Agents need governed access to metadata, semantics, lineage, metrics, and operational knowledge.
Clear permissions
An agent should know what it can read, what it can propose, and what it can execute.
Workflow-aware tooling
The system should connect to the actual places where work happens, not only a chat window.
Reviewable outputs
Engineers need to inspect plans, generated artifacts, and action history.
Feedback loops
When the agent is corrected, that correction should improve future work instead of disappearing into a single chat thread.
This is why the category is better understood as agentic data engineering than as generic automation. The useful part is not just that something happens automatically. The useful part is that the system can reason over context and take bounded actions across a workflow.
The role of the data engineer does not disappear
In a practical autonomous model, the data engineer’s role shifts upward.
Less time goes to:
- re-finding known information
- rewriting standard patterns
- manually stitching context together
- serving as the only bridge between tools
More time goes to:
- defining semantic logic and business rules
- improving metadata and context quality
- designing approval flows and guardrails
- evaluating reliability and failure modes
- shaping reusable workflow patterns
That is a healthier operating model. It makes engineering judgment more leveraged rather than more overloaded.
Final takeaway
Autonomous data engineering, done well, is not a story about removing people from the loop. It is a story about removing unnecessary manual reconstruction from the loop.
The strongest implementations are grounded in structured context, integrated with the existing data stack, and disciplined about where autonomy begins and ends. They help teams move faster on the parts of the workflow that are repetitive, fragmented, and expensive to coordinate by hand.
That is what autonomous data engineering actually looks like in practice: not magic, not total replacement, and not a chatbot with warehouse access.
It looks like context-aware agents doing bounded, useful work inside real data workflows.
Internal next reads
If you are mapping the category in more detail, the most useful next reads are:
- Agentic Data Engineering vs Traditional Data Engineering for the broader operating model comparison
- The Operating Model of an Agentic Data Team for team structure, governance, and responsibilities
- Agentic ETL: What Changes Beyond Traditional ETL for workflow-level changes in pipeline automation
Next steps
- Read Agentic Data Engineering vs Traditional Data Engineering
- Read The Operating Model of an Agentic Data Team
FAQ
What is autonomous data engineering?
Autonomous data engineering is the use of AI agents to carry parts of data engineering work from intent to execution using structured context, tool access, and explicit controls. In practice, it usually means bounded automation with human review, not unattended production ownership.
Is autonomous data engineering the same as agentic data engineering?
They are closely related, but agentic data engineering is usually the more useful term because it emphasizes workflow participation, reasoning, and tool-using behavior. Autonomous data engineering can sound broader than what most teams should actually implement.
What are the best first use cases?
Good starting points include asset discovery, impact analysis, SQL and model scaffolding, test generation, metric troubleshooting, and workflow preparation for review. These areas tend to have repeatable patterns and lower risk than uncontrolled production changes.
Does this replace data engineers?
No. It changes where engineers spend time. The goal is to reduce repetitive coordination work and make context reusable, while engineers focus more on semantics, controls, architecture, and evaluation.
What makes autonomous data engineering reliable?
Reliability comes from structured context, semantic clarity, lineage awareness, bounded permissions, workflow-aware execution, validation, and human oversight. Better prompting alone is not enough.
Start with Datus
- Studio: Datus Studio Overview
- GitHub: https://github.com/Datus-ai/Datus-agent
- Docs: Datus Docs
- Main site: https://datus.ai